Gordon Cormack (gvcormac@uwaterloo.ca)
Tom Lynam (trlynam@uwaterloo.ca)
Last revised July 16, 2007
TREC 2007 Spam (and Email) Track Guidelines
Overview
- Participants will prepare up to four versions of a filter to run on data using the TREC Spam Filter Evaluation Toolkit.
- Filters and results will be submitted to NIST using a Web interface. Details will be posted here and on the mailing list.
- The will be two kinds of data
- Private data -- filters will be run by the TREC coordinators; participants will not be involved
- Public data -- filters will be run by participants; public data will be released by TREC coordinators following filter submission; results to be submitted to NIST.
- Participants will run their filters using the same toolkit on public data that
will be released following filter submission.
- Each filter will be evaluated in three modes of operation (implemented by the toolkit)
- Immediate feedback (same as TREC 2005/2006, in which the correct classification of
each message is given to the filter immediately after it makes its prediction)
- Delayed feedback (same as TREC 2006, but with more extreme delay). The correct classification is given to the filter after it makes its prediction, or may never be given to the filter.
- On-line active learning. The filter is given a feedback quota. When it classifies a message, the filter may return a code requesting the true classification, which is
subsequently communicated to it by the toolkit, so long as the quota is not exceeded.
Filters not specifically programmed for active learning will nevertheless be subject to
the active learning test using a default feedback strategy -- feedback will be provided
for every message until the quota is exhausted. Details of the active
learning task.
TREC 2007 Submission Deadlines
- July 12, 2007 - deadline for filter submission to NIST web site
- July 13, 2007 - public corpora released to participants
- August 22, 2007 - deadline for results (on public corpora) submission to NIST web site
- September, 2007 - speaker proposals due at NIST
- November 2007 - TREC workshop at NIST in Gaithersburg, MD
Please subscribe to the mailing list.
TREC 2006 Spam (and Email) Track Guidelines
The 2006 track will reprise the 2005 experiments with new filters and data, and will
also investigate delayed feedback and active learning.
There are two tasks:
- On-line Filtering - enhancement to TREC 2005 task.
Each filter will be subjected to two versions of
the on-line filtering task:- Ideal user feedback - same as TREC 2005. Participants will
prepare a spam filter to operate with the TREC 2006 Spam Filter Evaluation Toolkit.
The task is identical to the TREC 2005 task -- participant filters will be
run (by TREC) on private corpora, and particpants will run their filters on
public corpora, which will be provided by TREC. Sample public corpora
are available now. See the 2006 toolkit description and the 2005 guidelines
below (TREC 2005) for details of the task. See also
NOTES ON DEADLINES, FILTER EFFICIENCY and ROBUSTNESS.
- Delayed Feedback - extension to TREC 2005. Spam filter preparation
is the same as for the On-line Filtering task. However, feedback (i.e. the
"train" command) will not be immediate. Random-sized sequences of email
messages will be classified without any intervening "train" commands. The
The corresponding "train" commands for these messages will follow, with
no intervening "classify" commands. That is, the test consists of
a sequence of messages to be classified, a sequence of train commands
for those messages, another sequence of messages to be classified, and
so on. The length of the sequences will be randomly generated with
an exponential distribution. (For the first several messages - until
10 ham and 10 spam are seen - the feedback will be ideal; that is, the
sequence size will be 1. Thereafter, the average sequence size will be
1000.)
The
2006 toolkit has been extended to support special
corpus indexes that indicate the feedback regimen. From the participant's
point of view, the delayed feedback runs will simply be different corpora
to which the filters are applied.
- Active Learning - completely new task.
The spam filter will
be given a large set of messages, without classification. The spam filter
will request the true classification for a subset of the messages, then
will classify a sequence of unlabelled messages. A new Active Learning Shell
supplied by TREC implements a rudimentary active learning method. Participants
enhance the active learning shell.
Sign up for the mailing list to participate in shaping TREC 2006.
Important notes from the mailing list
Due dates:
- February 22, 2006 - TREC Call for Participation was due. If you want to participate, send NIST email now.
- Spring 2006 - now - tasks are defined, training data is available, groups begin to prepare systems
- July 13, 2006 - deadline for filter submission to NIST web site
- July 14, 2006 - public corpora released to participants
- August 23, 2006 - deadline for results (on public corpora) submission to NIST web site
- September, 2006 - speaker proposals due at NIST
- November 2006 - TREC workshop at NIST in Gaithersburg, MD
May 14, 2005: Final guidelines
The deadlines and tasks are now finalized. We are in the process of
preparing a revised document, but there will be no material changes
from the description that is found here.
NOTE: Participants must submit intention to participate in TREC
See Call to TREC 2005. While
the official deadline has passed, applications will still be considered
at this time.
January 21, 2005
Prototype
TREC Spam Filter Evaluation Toolkit is available for
download.
Presentation slides
and Video presentation from
The 2005 Spam Conference.
Summary
An automatic spam filter classifies a chronological sequence of email messages as SPAM or HAM (non-spam).
The subject filter is run on several email sequences, some public and some private. The performance
of the filter is measured with respect to gold standard judgements by a human assessor.
Objectives
- To provide a standard evaluation of current and proposed SPAM filtering approaches.
- To establish an architecture and common tools and methodology for an open-ended
network of evaluation corpora (public and private).
- To lay the foundation for more general email filtering and retrieval tasks.
To join the list send a mail message to listproc@nist.gov
such that the body consists of the line
subscribe trecspam
There's an archive of the list. You should receive the password once you subscribe.
There's also a summary and taxonomy of the voluminous discussion
that has taken place as of February 25, 2005. You'll find the
password for that site in the list archive under the thread "Taxonomy."
The Task
A filter to be evaluated must be packaged so as to implement the following command-line commands, to execute on either Windows XP, Linux, or Solaris, as
outlined below. Details
are packaged with the
Evaluation Toolkit
initialize
classify emailfile resultfile
train ham emailfile resultfile
train spam emailfile resultfile
finalize
"Initialize" will install the system and configure it to process a single email
sequence. "Classify" will be called by the evaluation system once for every
email message in the sequence. "Classify" must return a result file
with three components: judgement ("ham" or "spam"), score (a real
number such that a higher number indicates higher likelihood that the message
is spam), and system info (up to 1kb of data which will be passed
back to the filter, but is otherwise unused by the evaluation system).
"Train ham" and "train spam" communicate the gold standard judgement from
the evaluation system to the filter. Each "classify" command will be
immediatedly followed by either "train ham" or "train spam" (communicating
the gold standard judgement) and the same emailfile and resultfile
from the preceding classify command.
"Finalize" will terminate and uninstall the system, removing any processes,
files, or settings created by the other commands.
A preliminary implementation of a simple spam filter implementing this interface
was provided by the coordinators in early 2005. The interface will
be finalized several weeks before the submission deadline.
Testing Procedure
Prior to testing, an assessor will assemble an email sequence, and enter
a gold-standard judgement for each message. An automated test jig will
run the target filter against the email sequence, using the interface
described above. The test jig will produce a raw result file for
further analysis. For each email message, in sequence, the raw result
file contains:
unique-identifier filter-judgement gold-standard-judgement filter-score
For TREC 2005, network access will be prohibited. A time limit of
approximately 2 seconds per message (average) will be enforced. The
largest test runs may be assumed to contain no more than 100,000
messages.
A preliminary implementation of the automated test jig was be provided by
the coordinators in early 2005. Sample email sequences and gold-standard
judgements suitable for use with the jig are included.
Evaluation
Evaluation measures will be based on those proposed in A Study of Supervised Spam Detection by
Cormack and Lynam - http://plg.uwaterloo.ca/~gvcormac/spamcormack . The primary measures are:
- ham misclassifaction rate (hmr). What fraction of ham messages are misclassified as spam?
- spam misclassifaction rate (smr). What fraction of spam messages are misclassified as ham?
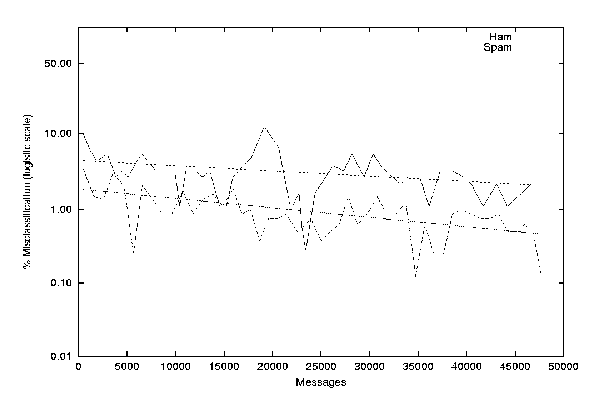
- ham/spam learning curve. Error rates as a function of number of messages processed. (see figure below left)
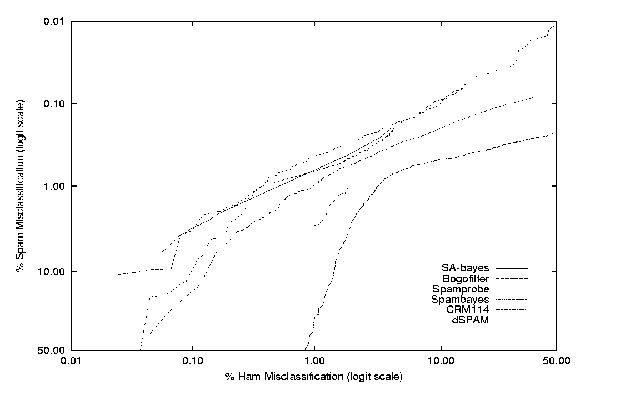
- ham/spam tradeoff curve. ROC (Receiver Operating Characteristic) curve. (see figure below right)
- ROC ham/spam tradeoff score ROC area above the curve. An equivalent definition of ROC area is the probability that a the spamminess score
of random ham message equals
or exceeds the spamminess score of a random spam message.
Other measures and methods of failure analysis will be investigated as the
track takes shape. The following combined ham/spam
misclassification score is under consideration:
- logistic mean error rate (lmr). Defined as lmr = logit-1(logit(hmr)/2 + logit(smr)/2)
where logit(x) = log(x/(1-x)) and logit-1(x) =
ex/(1+ex). This measure rewards equally
the same multiplicative factor improvement in either hmr or smr.
For the purpose of stratified analysis, at least one test corpus will be classified into genres
such as
- ham sent by a regular correspondent
- ham sent by a first-time sender
- ham sent by a news digest service
- ham sent as part of an internet transaction
- ham containing an appropriate non-delivery message
- spam that advertises a product
- spam that is/contains a virus
- spam bounced from an auto-responder containing an inappropriate
delivery message.
Public and Private Data
Each run requires an email sequence and corresponding gold-standard
judgements. Privacy considerations constrain the construction of
public data sets; real email is likely to be sensitive while public
email may not be representative. To address this issue, two sets of runs
will be performed, each using the test jig described above.
For the runs using public data, the coordinators will assemble from public
sources a sequence of ham and spam that resembles a real user's email as
closely as possible. A training sample will be supplied in advance, and
a larger test corpus will be supplied for the actual runs. Raw result files
will be submitted to TREC.
For the runs using private data, a number of assessors who have access to
real email will be recruited. Each assessor will be responsible for
assembling the email sequence and gold standard. A toolkit will be provided
for this purpose. Each participant must submit to TREC an executable version
of the filter, and license TREC to use the filter to carry out the experiments.
Each assessor will run the filter on the data and submit the raw result file to
the coordinators for analysis.
Submissions
Training data will be available Spring 2005. Software conforming to the
specified interface should be submitted to TREC Summer 2005. Following
the software submissions, data will be made available for the public data
runs. These runs should use exactly the same software submitted previously
to TREC. Raw results from the public data runs must be submitted to TREC.